En résumé
Autour du modèle OMOP, la communauté OHDSI a développé une suite cohérente d’outils open source qui couvre tout le cycle de vie d’une étude : préparer les données (WhiteRabbit, Rabbit-in-a-Hat, Usagi), explorer les concepts médicaux (ATHENA), définir des cohortes et analyses sans coder (ATLAS), contrôler la qualité (ACHILLES, DQD), et conduire des analyses avancées en R (HADES). À cela s’ajoutent un installeur Docker (Broadsea), un orchestrateur d’études réseau (Strategus) et un jeu de données d’apprentissage (Eunomia). Cet article dresse le portrait de chaque outil et de la façon dont ils s’articulent.
Une suite intégrée, pas des outils isolés
À première vue, la liste des outils OHDSI peut donner le tournis. Mais ils ne sont pas des projets indépendants : ils forment un pipeline cohérent qui suit le cycle de vie d’une étude observationnelle.
Le parcours typique suit quatre grandes étapes :
Préparer la base
Comprendre les données sources, concevoir l’ETL, aligner les codes locaux sur les vocabulaires standards.
Explorer les vocabulaires
Choisir les bons concepts standards pour définir ses cohortes.
Définir et analyser
Créer des cohortes, caractériser des populations, estimer des effets, construire des modèles prédictifs.
Contrôler la qualité
Vérifier que les données respectent les conventions OMOP avant d’engager des analyses ou de partager la base avec des partenaires.
Chaque outil OHDSI couvre une partie de ce parcours. Tous communiquent grâce au format commun : le modèle OMOP CDM.
Le Book of OHDSI comme référence
Cet article dresse un panorama. Pour chaque outil, la documentation officielle est dans le Book of OHDSI — gratuit, en anglais. Les chapitres 6 (ETL), 8 (Analytics Tools) et 9 (SQL and R) en sont les points d’entrée.
ATHENA — le dictionnaire des concepts
ATHENA est le dictionnaire de référence des vocabulaires standardisés OMOP. C’est l’outil que vous ouvrirez en tout premier — souvent même avant d’avoir des données.
- Rôle :
- Dictionnaire en ligne pour explorer les concepts standards OMOP et télécharger des sous-ensembles de vocabulaires.
- Période active :
- 2015 — 2025 (toujours maintenu)
- Liens :
- App en ligne · Code source (74 ★)
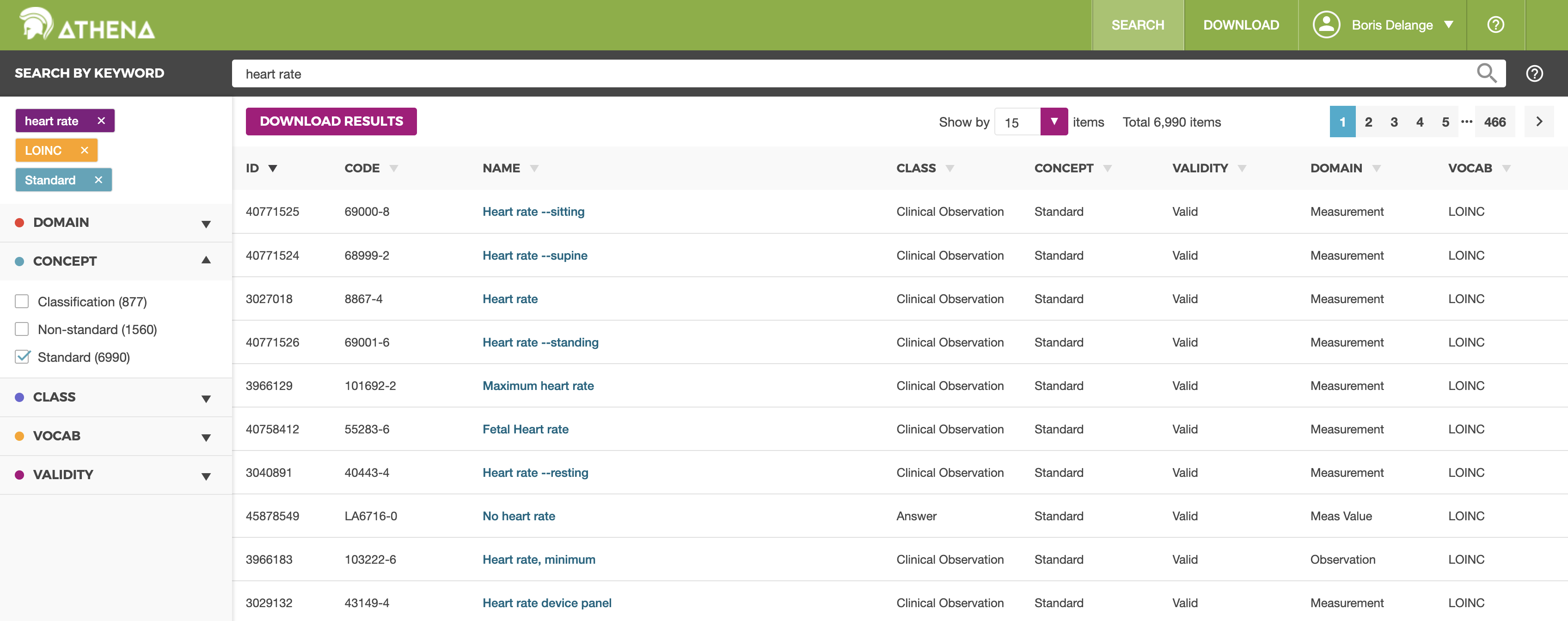
ATHENA donne accès à l’ensemble des vocabulaires intégrés par OHDSI — SNOMED CT, LOINC, RxNorm, ATC, CIM-10, CIM-9, MeSH, et bien d’autres. La liste exacte évolue au fil des mises à jour. Pour chaque concept, vous pouvez consulter :
- Son identifiant standard OMOP (concept_id), à utiliser dans vos requêtes
- Ses synonymes dans plusieurs langues
- Ses relations avec d’autres concepts (parent/enfant, équivalence, alignement)
- Son domaine (Condition, Drug, Measurement, Procedure…)
- Sa hiérarchie (par exemple, Diabète de type 2 est un enfant de Diabète)
Sans compte, on peut consulter le dictionnaire en lecture seule. Avec un compte gratuit, on peut télécharger des sous-ensembles de vocabulaires pour les importer dans sa propre base OMOP — étape obligatoire pour faire fonctionner ATLAS ou les autres outils.
Préparer l’ETL : WhiteRabbit, Rabbit-in-a-Hat, Usagi
Trois outils OHDSI accompagnent la phase de préparation de l’ETL — la conversion de votre base source vers OMOP. Tous sont des applications de bureau (Java, multiplateforme).
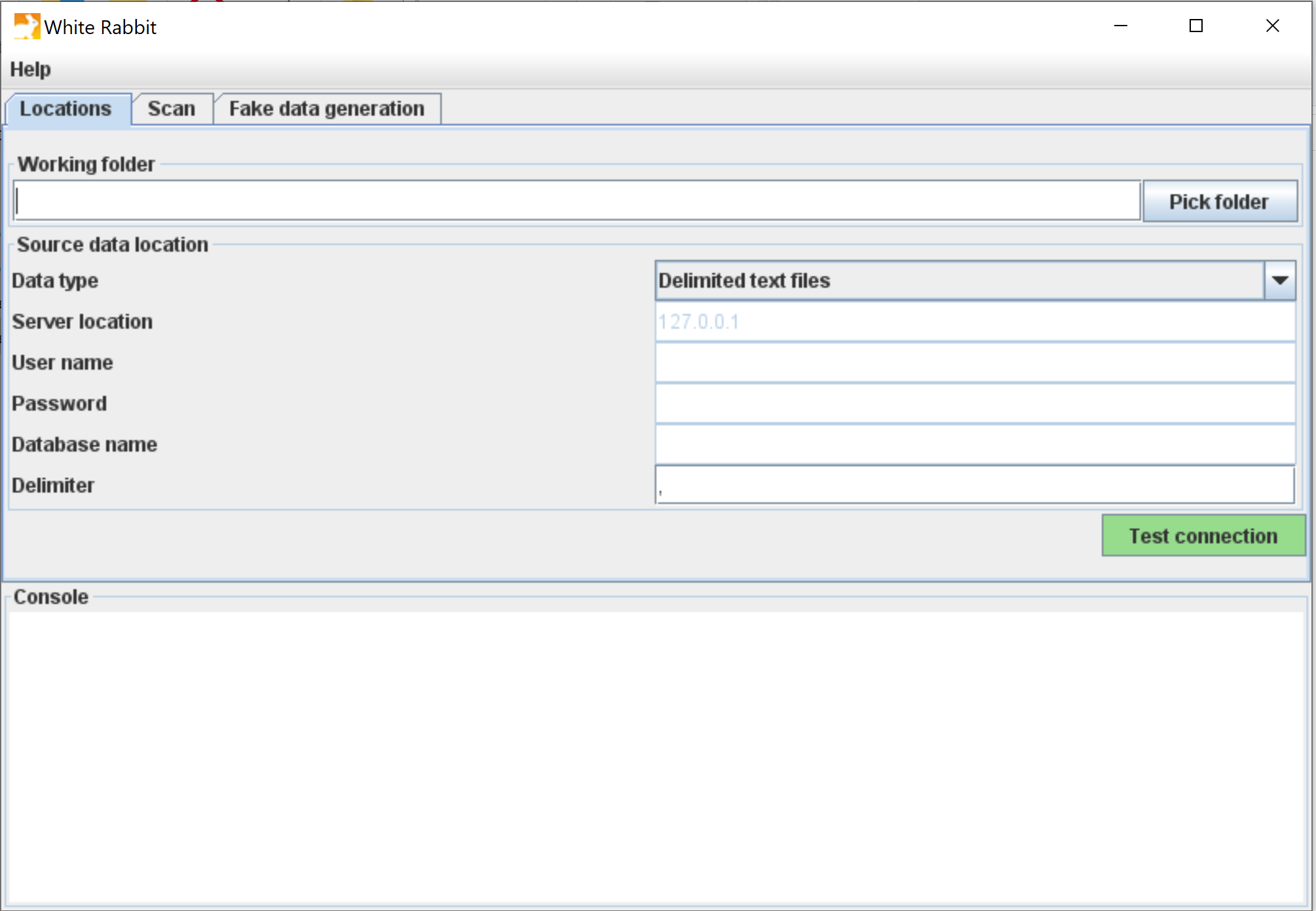
WhiteRabbit — scanner les données sources
WhiteRabbit est le premier outil que vous lancerez.
- Rôle :
- Application de bureau (Java) qui scanne une base source et génère un rapport de profilage agrégé.
- Période active :
- 2014 — 2025 (toujours maintenu)
- Liens :
- Code source (215 ★)
Il scanne votre base source (CSV, Oracle, SQL Server, PostgreSQL…) et génère un rapport Excel détaillé : tables, colonnes, types de données, distributions de valeurs, fréquences. C’est l’équivalent d’un data profiling automatisé.
Le rapport ne contient que des statistiques agrégées, donc anonymes : il peut être partagé librement avec des collaborateurs externes, sans contraintes de confidentialité.
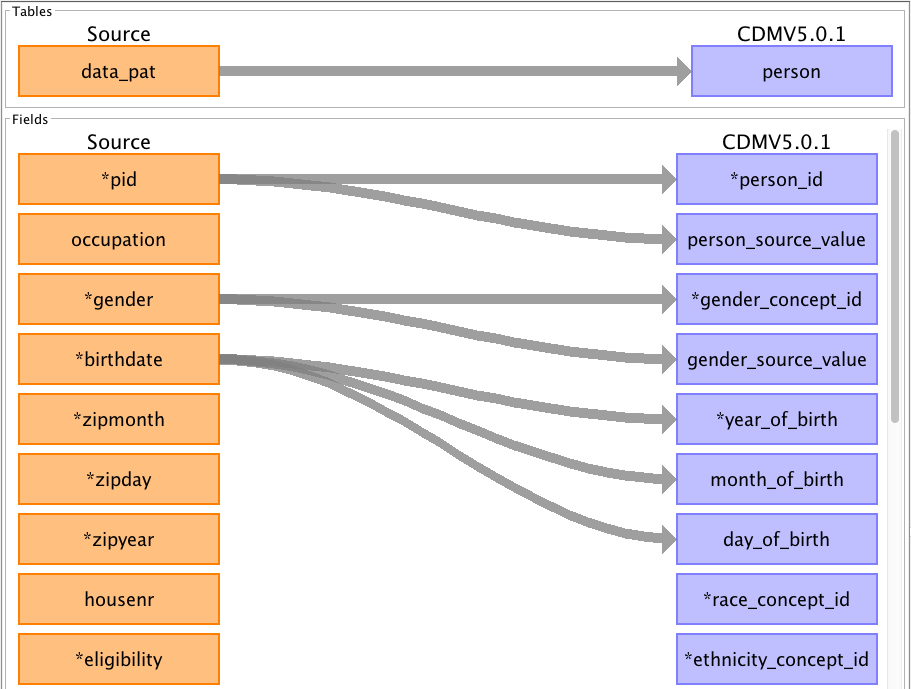
Rabbit-in-a-Hat — concevoir l’alignement table-à-table
À partir du rapport WhiteRabbit, Rabbit-in-a-Hat (disponible dans le même dépôt) propose une interface graphique pour dessiner l’alignement de votre base source vers OMOP. Vous y reliez vos tables source aux tables OMOP, vos colonnes source aux colonnes OMOP, et documentez la logique de transformation.
Le résultat est un document de spécification d’ETL qui guide l’implémentation effective (en SQL, Python ou R).
- Rôle :
- Application de bureau (Java) pour dessiner graphiquement le mapping table-à-table d’une base source vers OMOP.
- Période active :
- 2014 — 2025 (mutualisé avec le dépôt WhiteRabbit, toujours maintenu)
- Liens :
- Code source (mutualisé avec WhiteRabbit)
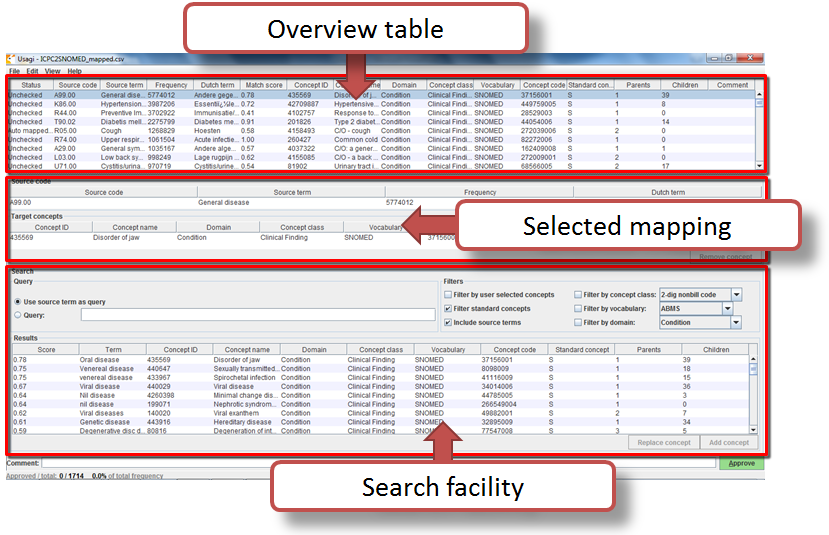
Usagi — aligner les codes sur les concepts standards
Une fois la structure alignée, il reste à convertir les codes locaux (par exemple, un code de service interne, une dénomination de médicament en texte libre) vers les concepts standards OMOP. C’est le rôle de Usagi.
- Rôle :
- Application de bureau (Java) qui suggère, par similarité textuelle, les concepts standards les plus proches des codes locaux à aligner.
- Période active :
- 2014 — 2024 (dernière mise à jour publique en 2024)
- Liens :
- Code source (113 ★)
Usagi prend en entrée la liste de vos codes locaux et propose, pour chacun, les concepts standards les plus proches en utilisant des algorithmes de similarité textuelle. Vous validez, corrigez ou rejetez chaque suggestion. Le résultat est exporté vers la table OMOP SOURCE_TO_CONCEPT_MAP, prévue précisément pour héberger ces correspondances locales.
ATLAS — la plateforme web
ATLAS est l’outil phare d’OHDSI : une plateforme web complète qui permet de concevoir et exécuter des analyses sur une base OMOP, sans écrire de code. C’est l’outil le plus visible de la communauté, celui que la plupart des chercheurs cliniques découvrent en premier.
- Rôle :
- Plateforme web pour définir cohortes, concept sets, caractérisations et études — sans code. Interface utilisateur de WebAPI et HADES.
- Période active :
- 2015 — 2026 (très actif)
- Liens :
- Démo publique · Code source (315 ★)
ATLAS permet, via une interface graphique :
- Explorer les vocabulaires localement (équivalent ATHENA dans votre base)
- Définir des concept sets (groupes de concepts réutilisables, par exemple « tous les antidiabétiques » ou « fréquence cardiaque » sous tous ses codes — un même concept clinique peut être couvert à plusieurs niveaux d’échelle et de granularité)
- Créer des cohortes à partir de critères d’inclusion/exclusion temporels
- Caractériser des populations (démographie, prévalence de comorbidités…)
- Estimer des effets (comparaisons de traitements avec ajustement)
- Construire des modèles de prédiction (machine learning sur cohortes)
- Générer du SQL automatiquement, exécutable sur toute base OMOP
ATLAS est l’interface utilisateur d’une couche d’analyses plus profonde (HADES, ci-dessous). On peut tester ATLAS sans installation, via la démo publique d’OHDSI qui tourne sur des données synthétiques.
Évaluer la qualité avec ACHILLES et le DQD
Une fois votre base OMOP construite, comment vérifier qu’elle est correcte ? Deux outils complémentaires sont conçus pour ça.
ACHILLES — caractériser la base
ACHILLES (Automated Characterization of Health Information at Large-scale Longitudinal Evidence Systems) est un package R qui scanne entièrement une base OMOP CDM et génère un rapport synthétique : nombre de patients, distribution des âges, des sexes, prévalences des conditions, fréquences des médicaments, distributions de mesures biologiques…
- Rôle :
- Package R qui caractérise une base OMOP (volumes, distributions, prévalences). Le résultat est visualisable dans ATLAS.
- Période active :
- 2014 — 2025 (toujours maintenu)
- Liens :
- Code source (147 ★)
Le résultat est consultable via ATLAS, qui intègre la visualisation d’ACHILLES. C’est l’outil de référence pour se familiariser rapidement avec une nouvelle base OMOP.
Data Quality Dashboard — vérifier les conventions OMOP
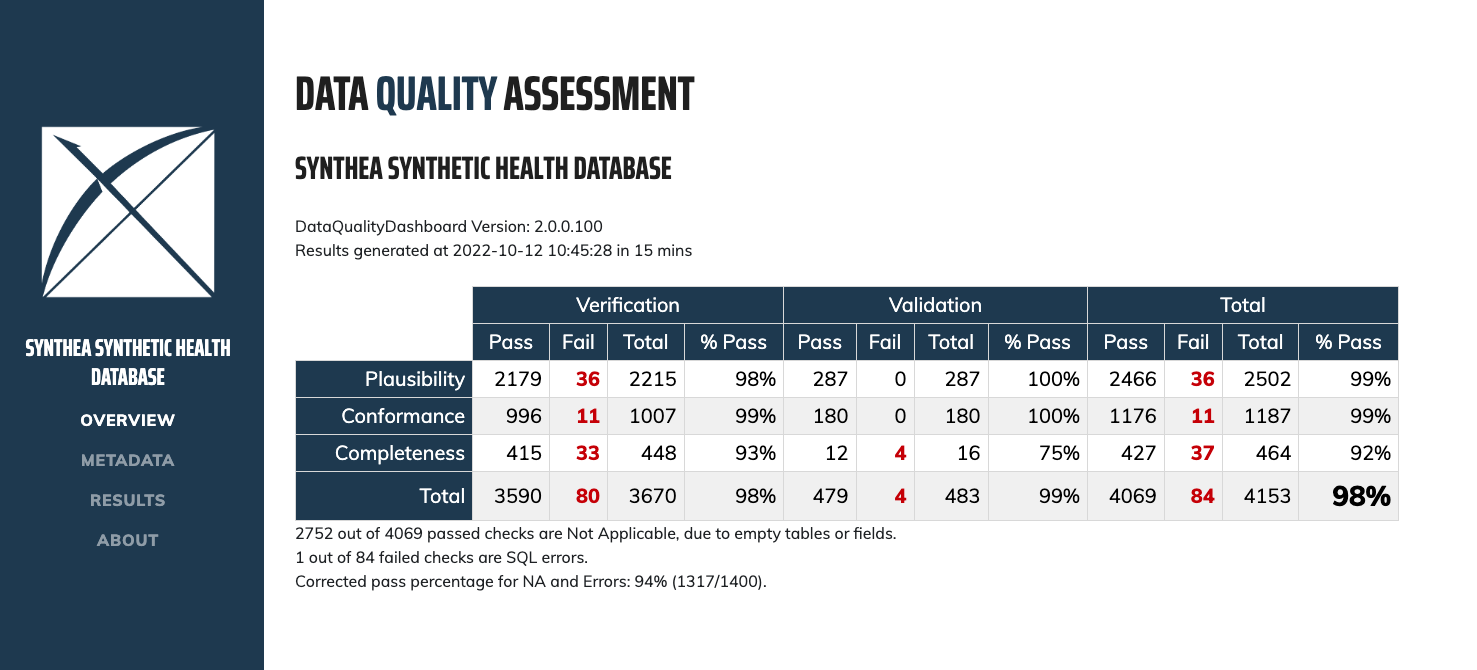
Le Data Quality Dashboard (DQD) va plus loin :
- Rôle :
- Package R qui exécute plusieurs milliers de contrôles automatisés sur une base OMOP et produit un tableau de bord HTML.
- Période active :
- 2019 — 2026 (très actif)
- Liens :
- Code source (176 ★)
Il exécute des milliers de contrôles automatisés sur votre base OMOP pour vérifier qu’elle respecte les conventions du modèle. Les contrôles sont organisés selon les trois grandes catégories du framework de Kahn, repris officiellement par la documentation du DQD :
- Conformance (conformité) — les types de données, les clés et les contraintes du schéma sont respectés.
- Completeness (complétude) — les champs obligatoires ne sont pas vides.
- Plausibility (plausibilité) — les valeurs sont dans des plages réalistes (ex. : pas de patient de 200 ans, pas de date de décès antérieure à la naissance).
Le rapport HTML interactif facilite l’identification des problèmes prioritaires avant que la base ne soit utilisée pour des analyses.
HADES — l’analyse R à grande échelle
HADES (Health Analytics Data-to-Evidence Suite) est l’ensemble des packages R officiels d’OHDSI pour la recherche observationnelle programmatique.
- Rôle :
- Méta-package qui regroupe et coordonne l’ensemble des packages R officiels d’OHDSI pour la recherche observationnelle.
- Période active :
- 2020 — 2026 (très actif ; packages individuels actifs depuis 2014)
- Liens :
- Documentation · Code source (28 ★ ; les packages individuels ont leurs propres dépôts, par ex. PatientLevelPrediction 216 ★, CohortMethod 89 ★)
Ces packages s’articulent autour de blocs cohérents :
DatabaseConnectoretSqlRender— couche d’abstraction pour exécuter du SQL sur n’importe quelle base OMOP (PostgreSQL, SQL Server, Oracle, BigQuery, Redshift…).CohortGeneratoretCohortMethod— création et comparaison de cohortes.Characterization— description automatisée des cohortes.PatientLevelPrediction— modèles de prédiction validés par patient.SelfControlledCaseSeries,Cyclops,MethodEvaluation— méthodes statistiques avancées.
HADES est l’outil de prédilection des data scientists et statisticiens qui travaillent sur OMOP. C’est aussi le moteur sous-jacent d’ATLAS : quand vous générez une analyse via ATLAS, c’est in fine du code HADES qui s’exécute.
La documentation centrale couvre l’ensemble des packages.
Autres outils utiles à connaître
Au-delà des outils précédemment décrits, plusieurs autres méritent d’être mentionnés — soit parce qu’ils accompagnent le quotidien des équipes, soit parce que vous les croiserez dans la documentation ou les déploiements existants.
Déploiement et orchestration
- Broadsea — l’installeur Docker officiel de l’écosystème OHDSI. Une seule commande déploie ATLAS, WebAPI, HADES dans RStudio, Ares, et plusieurs services optionnels. C’est aujourd’hui la voie standard pour mettre en place OHDSI dans une institution.
- Strategus — un orchestrateur R qui enchaîne les modules HADES pour concevoir, exécuter et partager des études réseau multi-sites. C’est le format moderne de packaging d’une étude OHDSI, qui remplace progressivement les anciens study packages artisanaux.
- Ares — une interface web pour explorer les résultats d’ACHILLES et du DQD à l’échelle d’un réseau de bases OMOP, avec comparaisons entre sites et entre versions d’une même base.
Apprendre et tester
- Eunomia — un petit jeu de données OMOP distribué sous forme de fichier SQLite, utilisé par presque tous les tutoriels et tests unitaires de l’écosystème. Utile pour expérimenter HADES sans avoir accès à une base réelle.
Définir et valider des cohortes
- CohortDiagnostics — un outil R/Shiny pour diagnostiquer la qualité d’une définition de cohorte : flux d’attrition, codes orphelins, incidence, comparaisons entre bases.
- PhenotypeLibrary — une bibliothèque communautaire de définitions de cohortes validées et versionnées (avec DOI), réutilisables d’une étude à l’autre.
- Capr — pour définir des cohortes programmatiquement en R, en alternative à l’interface graphique d’ATLAS.
- PHOEBE — un assistant qui suggère, à partir d’un concept donné, les concepts apparentés que vous oubliez peut-être d’inclure dans un concept set. Intégré directement dans ATLAS depuis la version 2.12.
Qualité ETL côté EHDEN
- CdmInspection — un package R maintenu par la fondation EHDEN (et non par OHDSI directement) qui génère un rapport d’inspection d’une base OMOP. Utilisé dans le processus d’onboarding des partenaires européens de données.
Tout est open source
L’intégralité du code source de ces outils est sur le compte github.com/OHDSI, sous licence Apache 2.0. Cela signifie :
- Vous pouvez lire le code, comprendre exactement comment chaque analyse est calculée.
- Vous pouvez contribuer des correctifs ou des fonctionnalités.
- Vous pouvez forker un outil pour vos propres besoins, y compris commerciaux.
La communauté accueille les contributions externes via pull requests, avec un processus de revue documenté. Les outils les plus actifs (ATLAS, HADES) reçoivent des contributions tous les mois.
Pour aller plus loin
Cet article est un panorama. Pour entrer dans le détail :
- Le Book of OHDSI est la documentation de référence. Chapitre 6 pour l’ETL (WhiteRabbit, Usagi…), chapitre 8 pour ATLAS et la Methods Library, chapitre 9 pour SQL et R.
- L’EHDEN Academy propose des formations gratuites en ligne pour chaque outil — c’est le meilleur point d’entrée pratique pour les débutants.
- La démo ATLAS publique permet de tester sans installation.
- Le GitHub OHDSI centralise tous les dépôts, avec README et exemples pour chaque outil.
- L'écosystème OHDSI n'est pas une collection d'outils indépendants, c'est une suite cohérente qui couvre tout le cycle d'une étude observationnelle : préparer, explorer, analyser, contrôler.
- ATHENA est le dictionnaire des concepts standardisés — le premier outil à consulter, avec ou sans données.
- WhiteRabbit + Rabbit-in-a-Hat + Usagi accompagnent la phase d'ETL : scanner les données, aligner les tables, aligner les codes.
- ATLAS est la plateforme web phare : définir des cohortes, caractériser, estimer, prédire — sans coder.
- ACHILLES et le Data Quality Dashboard garantissent que la base OMOP respecte les conventions du modèle avant d'engager des analyses.
- HADES regroupe l'ensemble des packages R officiels d'OHDSI pour les analyses programmatiques — c'est aussi le moteur d'ATLAS.
- Pour déployer l'écosystème, Broadsea fournit un installeur Docker prêt à l'emploi ; pour les études réseau, Strategus est le format de packaging récent.
- Tout est open source sur GitHub, sous licence Apache 2.0, avec une documentation gratuite (Book of OHDSI, EHDEN Academy).
