En résumé
Le modèle OMOP CDM est devenu le standard mondial pour structurer les données de santé observationnelles. Né d’un projet américain de pharmacovigilance dans le sillage du FDA Amendments Act de 2007, son objectif était simple : permettre de comparer des analyses entre bases de données différentes. Une étude réseau marquante publiée en 2016 a démontré que l’approche fonctionnait — et a ouvert la voie à tout ce qui a suivi.
Ce que vous savez déjà
Si vous avez suivi les articles de la section Comprendre les entrepôts de données de santé, vous avez déjà une bonne intuition des problèmes que résout OMOP :
- Les données de santé sont dispersées dans de multiples logiciels hospitaliers, chacun avec son propre format (premier article).
- Pour les exploiter en recherche, il faut les rassembler dans un entrepôt de données de santé (EDS) via un processus d’ETL (troisième article).
- Ces données sont organisées en tables reliées entre elles, au format long (cinquième article).
- Chaque hôpital utilise des codes différents pour désigner la même chose — d’où le besoin de terminologies standardisées (sixième article).
OMOP est la réponse à tous ces problèmes : un modèle de données commun qui définit à la fois la structure des tables (interopérabilité structurelle) et les vocabulaires à utiliser (interopérabilité sémantique).
Mais pour comprendre pourquoi OMOP s’est imposé, il faut remonter à ses origines.
Les origines : le projet OMOP
Un problème de pharmacovigilance
Aux États-Unis, le FDA Amendments Act de 2007 a donné mandat à la FDA de développer un système permettant d’utiliser les données de santé déjà collectées pour identifier les risques liés aux médicaments commercialisés (Stang et al., 2010).
La question de fond : peut-on utiliser les données de santé déjà collectées en routine (bases de données d’assurance maladie, dossiers hospitaliers, registres) pour détecter les effets indésirables des médicaments avant qu’une catastrophe ne survienne ?
La création du projet OMOP
C’est dans ce contexte qu’est né le projet OMOP, sous la forme d’un partenariat public-privé présidé par la FDA, administré par la FNIH, et financé par un consortium d’organisations de l’industrie pharmaceutique (Stang et al., 2010).
OMOP s’est donné un programme de deux ans pour tester empiriquement quelles méthodes statistiques permettent de détecter de façon fiable les associations médicament–événement à partir de bases de remboursement et de dossiers patients informatisés (Stang et al., 2010). Plus de dix catégories de méthodes différentes (analyses de disproportion, approches cas-témoins, propensity scoring, méthodes séquentielles…) ont été comparées sur un même ensemble de cas d’usage.
Les cas d’usage choisis couvraient des associations connues servant de référence — par exemple le risque d’angio-œdème sous inhibiteurs de l’enzyme de conversion de l’angiotensine, d’hémorragies sous warfarine, ou d’atteinte hépatique aiguë sous certains antibiotiques — afin de mesurer la capacité de chaque méthode à retrouver ces signaux. Le programme évaluait également des associations bénéfiques, comme la réduction de la mortalité après infarctus par les bêta-bloquants.
Le Common Data Model
Pour comparer les méthodes sur différentes bases de données, les chercheurs du projet OMOP avaient besoin d’un format commun. Ils ont donc créé le Common Data Model (CDM) : un schéma relationnel dans lequel toutes les bases de données partenaires devaient transformer leurs données (Stang et al., 2010).
Bases sources hétérogènes
Entrepôt CHU A
patient_id, dx_cim10, date_diag
Entrepôt CHU B
nip, diagnostic, code_cim, dt
Base d’assurance maladie
benef_id, ald_code, periode
Registre national
registry_id, cond_code, occured_on
au CDM
Format OMOP CDM
condition_occurrence
person_id, condition_concept_id,
condition_start_date,
condition_source_value, …
Mêmes tables, mêmes colonnes, mêmes vocabulaires standards — quelle que soit la base source.
Le CDM repose sur quelques principes clés, explicités par la suite dans le Book of OHDSI :
- Centré sur le patient : chaque événement clinique est rattaché à un patient et daté.
- Standardisé sémantiquement : les codes locaux de chaque hôpital sont convertis vers des vocabulaires standards (SNOMED CT pour les diagnostics, RxNorm pour les médicaments, LOINC pour la biologie…). Stang et al. mentionnent dès 2010 l’intégration de CIM-9, CPT-4, SNOMED et LOINC.
- Agnostique de la technologie : le modèle peut être implémenté sur n’importe quelle base de données relationnelle (PostgreSQL, SQL Server, Oracle, BigQuery…).
- Traçable : les codes sources originaux sont conservés en parallèle des codes standards. Stang et al. précisent que le CDM « does not alter the content of the data ».
Ces choix sont détaillés dans un prochain article sur la structure du CDM.
Les résultats du projet
Le projet OMOP a produit deux contributions structurantes pour la suite :
- Une évaluation empirique des méthodes de détection de signaux de sécurité, conduite sur 10 bases de données couvrant plus de 130 millions de patients grâce au CDM (Ryan et al., 2012) — démontrant la faisabilité d’analyses à grande échelle à partir de sources hétérogènes.
- Les premières versions du Common Data Model et de son système de vocabulaires standardisés, qui seront repris et étendus par OHDSI à partir de 2014.
À la fin du projet OMOP, la communauté qui s’était formée autour de lui a choisi de poursuivre le travail au sein d’une organisation pérenne, fondée en 2014 : OHDSI. Nous lui consacrons l’article suivant.
Une nouvelle ère : Hripcsak 2016 et la première étude réseau internationale d’OHDSI
En 2016, la communauté OHDSI — issue d’OMOP et fondée en 2014 — a franchi une nouvelle étape avec une étude internationale publiée dans les Proceedings of the National Academy of Sciences (Hripcsak et al., 2016). Là où Ryan et al. avaient prouvé que les méthodes statistiques fonctionnaient sur un réseau de bases, Hripcsak et al. ont utilisé ce réseau pour répondre à une véritable question de pratique clinique : comment les patients atteints de diabète de type 2, d’hypertension ou de dépression sont-ils effectivement traités à travers le monde ?
L’étude a couvert 11 sources de données dans 4 pays (États-Unis, Royaume-Uni, Japon, Corée du Sud), soit plus de 250 millions de patients, en apportant ce que les auteurs eux-mêmes ont qualifié d’éclairage sur la pratique clinique jusqu’alors inaccessible.
Le principe technique : chaque institution exécutait le même code d’analyse sur ses propres données, au format OMOP CDM. Les résultats agrégés étaient ensuite consolidés à l’échelle internationale. Aucune donnée patient n’a circulé entre les centres.
Le résultat fut frappant : pour ces trois maladies pourtant couvertes par des recommandations internationales, les stratégies de prescription variaient considérablement d’un pays à l’autre. Plus de 10 % des patients atteints de diabète ou de dépression — et près de 25 % pour l’hypertension — suivaient un parcours thérapeutique unique dans toute la cohorte, jamais retrouvé chez un autre patient. Pour le diabète, la metformine dominait largement en première intention conformément aux recommandations, mais avec des rythmes d’adoption très variables selon les bases.
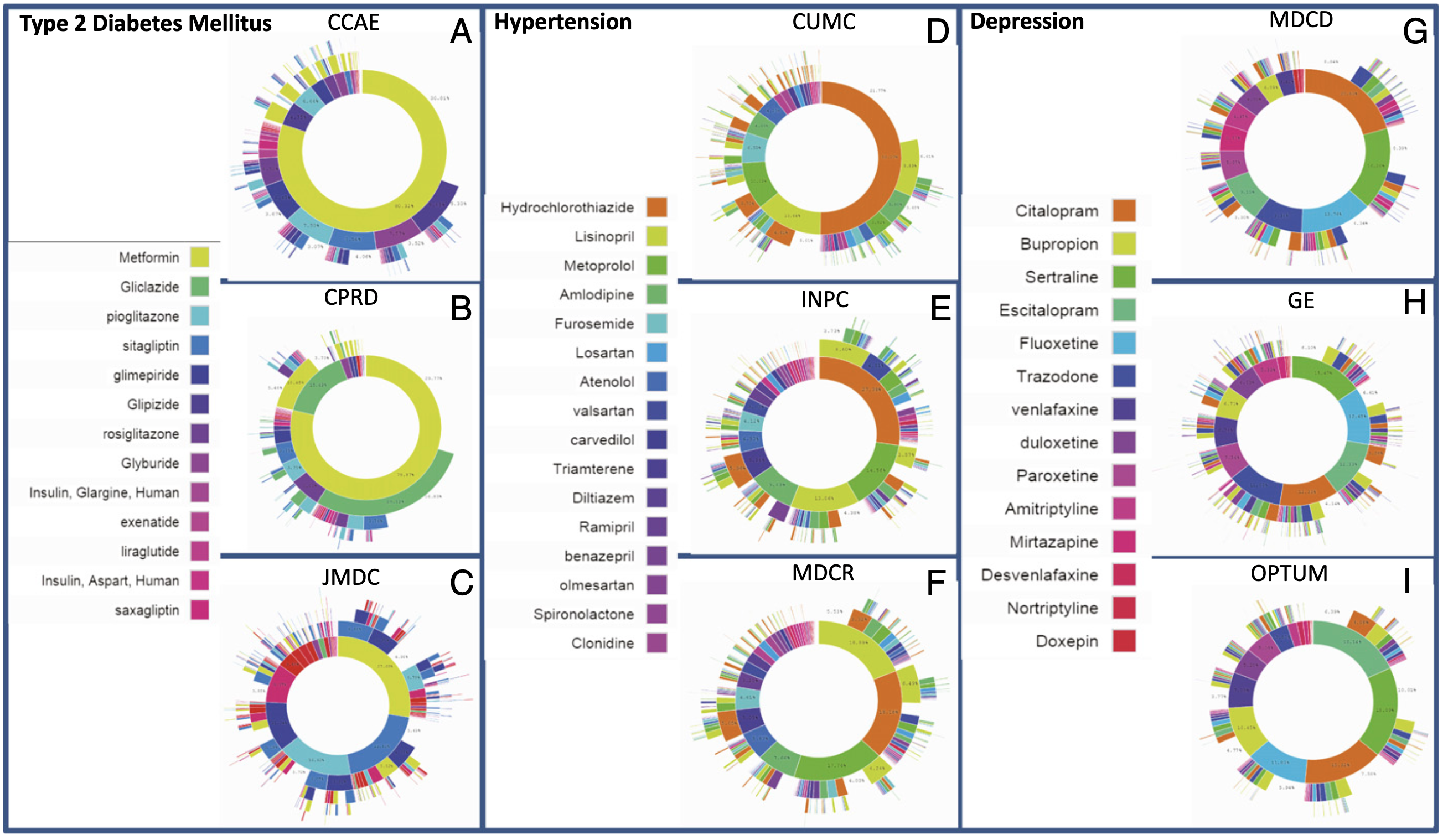
Figure 3 de Hripcsak et al., 2016. Pour chacune des trois maladies — diabète (A-C), hypertension (D-F), dépression (G-I) —, le cercle intérieur de chaque sunburst représente le premier médicament prescrit, le cercle suivant le médicament suivant, et ainsi de suite. Trois sources de données sont représentées par maladie. On voit nettement la dominance de la metformine pour le diabète, l’éclatement des choix pour l’hypertension, et la diversité encore plus grande pour la dépression. Cliquer sur l’image pour zoomer.
Pourquoi cette étude a marqué
Hripcsak et al. ne démontrent pas seulement que le modèle OMOP fonctionne techniquement — Ryan et al. l’avaient déjà établi quatre ans plus tôt. Cette étude prouve qu’une communauté ouverte peut désormais s’en servir pour répondre à de vraies questions cliniques internationales, sans déplacer les données patient. C’est l’acte de naissance des grandes études de pratique réelle qui suivront.
Cette étude a posé les fondations de tout ce qui a suivi : modèles de comparaison à grande échelle, études réglementaires en vie réelle, infrastructures nationales basées sur OMOP. La suite de cette section explore ces développements.
Et Linkr dans tout ça ?
Linkr intègre nativement le modèle OMOP CDM. La plateforme permet aux cliniciens d’exploiter des données au format OMOP sans avoir besoin de maîtriser le SQL ou les détails techniques du modèle — tout en offrant aux data scientists un accès complet au CDM pour des analyses avancées.
- OMOP est né d'un projet américain (présidé par la FDA, administré par la FNIH, financé par un consortium pharmaceutique) face à un besoin concret : détecter les effets indésirables médicamenteux dans les données de santé déjà collectées.
- Le Common Data Model définit à la fois la structure des tables (interopérabilité structurelle) et les vocabulaires à utiliser (interopérabilité sémantique).
- Le modèle est centré patient, standardisé sémantiquement, agnostique de la technologie, et traçable : les codes locaux sont toujours conservés à côté des codes standards.
- Deux études fondatrices marquent l'histoire d'OMOP : Ryan 2012 a prouvé que les méthodes statistiques fonctionnent sur un réseau de bases ; Hripcsak 2016 a prouvé que la communauté OHDSI peut s'en servir pour répondre à de vraies questions cliniques internationales.
- C'est cet enchaînement qui a légitimé toute l'infrastructure et la communauté qui se sont déployées ensuite.
